1. QtMips cache optimization
https://docs.google.com/spreadsheets/d/12hHgau6lgYAoWTDobTF0zBRuDMUZzYEFOYyo5p__UFA/edit?usp=sharing
Given the sorting algorithm code below, find an optimum cache configuration that balances cost of cache SRAM with execution time, including memory stalls due to cache misses.
-
Metric: cycles × cache bits -
Metric: cycles + cache bits
using:
-
Cycles:
-
CPU cycles
-
Memory stall cycles
-
-
Cache bits:
-
including overhead for tag, valid, etc. bits, not just data bits
-
(associativity does not affect this total)
-
Use the following configuration for all options:
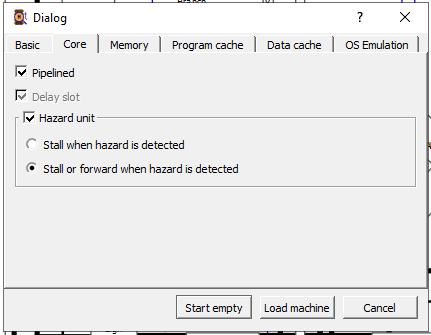
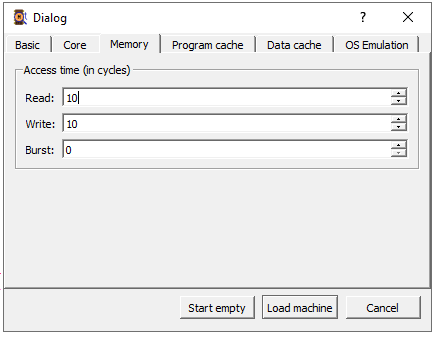
This means that any time the word is not present in cache, the CPU waits for 10 cycles to fetch the word from main memory.
Direct download: selection-sort-cache.S
// Simple sorting algorithm - selection sort
// Select the CPU core configuration with delay-slot
// Directives to make interresting windows visible
//#pragma qtmips show registers
//#pragma qtmips show memory
#pragma qtmips show cache_program
#pragma qtmips show cache_data
.set noreorder
.set noat
.globl array
.text
.globl _start
.ent _start
_start:
la $a0, array
addi $s0, $0, 0 //Minimum value from the rest of the array will be placed here. (Offset in the array, increasing by 4 bytes).
addi $s1, $0, 60 // Maximal index/offset value. Used for cycle termination = number of values in array * 4.
add $s2, $0, $s0 //Working position (offset)
// $s3 - offset of the smallest value found so far in given run
// $s4 - value of the smallest value found so far in given run
// $s5 - temporary
main_cycle:
beq $s0, $s1, main_cycle_end
nop
add $at, $a0, $s0
lw $s4, 0($at) // lw $s4, array($s0)
add $s3, $s0, $0
add $s2, $s0, $0
inner_cycle:
beq $s2, $s1, inner_cycle_end
nop
add $at, $a0, $s2
lw $s5, 0($at) // lw $s5, array($s2)
// expand bgt $s5, $s4, not_minimum
slt $at, $s4, $s5
bne $at, $zero, not_minimum
nop
addi $s3, $s2, 0
addi $s4, $s5, 0
not_minimum:
addi $s2, $s2, 4
j inner_cycle
nop
inner_cycle_end:
add $at, $a0, $s0
lw $s5, 0($at) // lw $s5, array($s0)
sw $s4, 0($at) // sw $s4, array($s0)
add $at, $a0, $s3
sw $s5, 0($at) // sw $s5, array($s3)
addi $s0, $s0, 4
j main_cycle
nop
main_cycle_end:
//Final infinite loop
end_loop:
//cache 9, 0($0) // flush cache memory
break // stop the simulator
j end_loop
nop
.end _start
.data
// .align 2 // not supported by QtMips
array:
.word 5, 3, 4, 1, 15, 8, 9, 2, 10, 6, 11, 1, 6, 9, 12
// Specify location to show in memory window
#pragma qtmips focus memory array1.1. Optimization dimensions
The Program cache and Data cache configuration is yours to optimize.
Translation between QtMips cache terminology to our terminology:
-
Num sets: num cache blocks
-
Block size: number of words in a block
Your baseline for comparison is the following performance:
-
Both program and data cache disabled
-
Cycles:
-
1780 PC cycles with 255 stalls (included in total)
-
Program memory stats:
-
1778 reads
-
16002 stall cycles
-
-
Data memory stats:
-
150 reads
-
30 writes
-
1620 stall cycles
-
-
Because the simulator doesn’t quite give enough information about when the CPU is stalled while fetching both program and data memory, use the sum of the stall cycles.
Total cycles: 1780 + 16002 + 1620 = 19402 cycles baseline
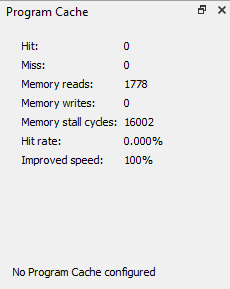
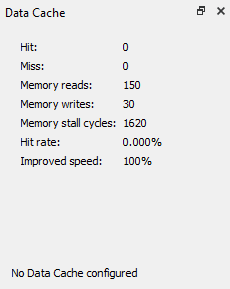
The limitation listed at
https://github.com/cvut/QtMips/blob/master/README.md#limitations-of-the-implementation
explains that the 1780 cycles listed on the data path display does not include memory stalls, or cycles waiting for results from main memory.
Bonus points for optimizing the code itself to execute fewer program cycles.
Reducing the number of stalls when the forwarding unit forces a nop is helpful for this.
You need to show that your optimized code yields exactly the same results as the original code!
| Using a non-pipelined CPU requires fewer cycles, but remember that this also forces a slower clock speed; assume that pipelining is the best option. |
1.3. Notes
You must "Compile source and update memory" before each run.
Learn the keyboard shortcuts to save time configuring, compiling+loading, and running.
1.4. qtmips_cli.exe usage
-
Navigate to the location of
qtmips_cli.exe -
Download the assembly file:
selection-sort-cache.Sto the same folder
From the Explorer folder that contains this file, right-click and select "Open MobaXterm terminal here"
Once MobaXterm opens, type ls to see the contents of this folder and verify that both files are listed
-
qtmips_cli.exe -
selection-sort-cache.S
Run the following command to get your baseline statistics:
./qtmips_cli.exe --pipelined --hazard-unit forward --read-time 10 --write-time 10 --burst-time 0 --dump-cycles --dump-cache-stats --asm selection-sort-cache.S
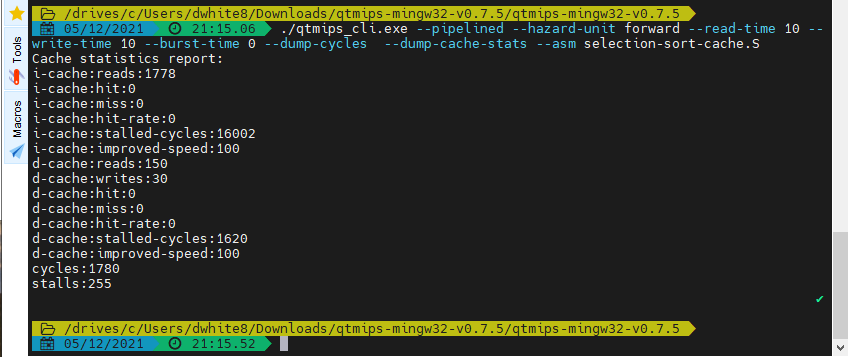
-
Cycles:
-
1780 PC cycles with 255 stalls (included in total)
-
Program memory stats:
-
1778 reads
-
16002 stall cycles
-
-
Data memory stats:
-
150 reads
-
30 writes
-
1620 stall cycles
-
-
⋯ which is the same as the previous baseline, as a cross-check.
Now you are ready to add the caches in various configurations.
Run the command ./qtmips_cli.exe -h to see the list of options.
For example:
-
Adding the following after
--dump-cache-statswill add a data cache of 8 sets of 1 word each, 1-level associativity, and least-recently-used replacement policy:-
--d-cache lru,8,1,1
-
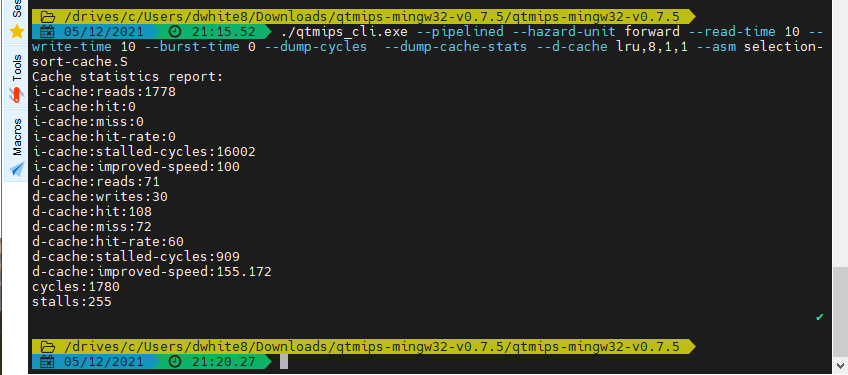
The cycles and instruction cache numbers stayed the same, while the data cache stalled cycles reduced from 1620 down to 909.
1.4.1. old version for historical reference
DO NOT USE THIS EXAMPLE
./qtmips_cli.exe --pipelined --read-time 10 --write-time 10 --burst-time 0 --dump-cycles --dump-cache-stats selection-sort-cache.mips-elf
-
1945 cycles, 255 stalls
-
17487 instruction stalls
-
1629 data stalls
-> 1945 + 17487 + 1629 = 21061 cycles baseline
These numbers are slightly different because there is a small amount of "bootstrap" code that is executed before and after the main code. You should use either the cli or the GUI numbers for your comparisons — don’t mix the numbers!
|
The specific assembly file that was compiled for the ELF executable was selection-sort-cache_elf.S.
The other files are present in the course’s root folder https://agnd.net/valpo/424/